## Install sfbulk2js npm package in your nodejs project
```
$ npm install -s sfbulk2js
+ sfbulk2js@0.0.1
added 2 packages from 2 contributors and audited 2 packages in 1.653s
found 0 vulnerabilities
```
### Now you are all set with the setup.
### Sample Code to load a CSV file into Case Object
- You can create this CSV from data store (like Postgres, Spanner, MySQL...) for the Case Object
- Here is the content of our CSV file: input.csv
```
$ cat input.csv
Subject,Priority
Engine cylinder has knocking,High
Wiper Blade needs replacement,Low
```
## Code to load the records in this CSV file to Salesforce Case Object using sfbulk2js
```
// filename:index.js
// test file for sfbulk2js
// author: mohan chinnappan (mar-18-2020)
const sfb2 = require('sfbulk2js'); // the npm package we just installed
const fs = require('fs');
const process = require('process');
// read access-token from the env
const AT = process.env.AT;
const cji = {
instanceUrl: 'https://mohansun-fsc-21.my.salesforce.com',
apiVersion: 'v46.0',
accessToken: `${AT}`,
contentType: 'CSV',
lineEnding: 'LF'
};
const waitTimeMs = 5000;
function sleep(ms) {
console.log('WAITING');
return new Promise(resolve => setTimeout(resolve, ms));
}
async function dataload(datafile) {
try {
console.log(`=== CREATE JOB === `);
const job = await sfb2.createJob(cji.instanceUrl, cji.apiVersion, cji.accessToken, 'insert', 'Case', cji.contentType, cji.lineEnding );
console.log(job);
console.log(`jobId: ${job.id}`);
console.log(`=== JOB STATUS === `);
let jobStatus = await sfb2.getJobStatus(cji.instanceUrl, cji.apiVersion, cji.accessToken, 'ingest', job.id );
console.log(`=== JOB STATUS for job: ${job.id} ===`);
console.log(jobStatus);
console.log(`=== PUT DATA === `);
const fdata = fs.readFileSync(datafile, 'utf8');
const putDataStatus = await sfb2.putData(cji.instanceUrl, cji.accessToken, job.contentUrl, fdata );
console.log(`=== JOB STATUS === `);
jobStatus = await sfb2.getJobStatus(cji.instanceUrl, cji.apiVersion, cji.accessToken, 'ingest', job.id );
console.log(`=== JOB STATUS for job: ${job.id} ===`);
console.log(jobStatus);
console.log(`=== PATCH STATAE === `);
const patchDataStatus = await sfb2.patchState(cji.instanceUrl, cji.apiVersion, cji.accessToken, job.id, 'UploadComplete' );
console.log(patchDataStatus);
console.log(`=== JOB STATUS === `);
jobStatus = await sfb2.getJobStatus(cji.instanceUrl, cji.apiVersion, cji.accessToken, 'ingest', job.id );
console.log(`=== JOB STATUS for job: ${job.id} ===`);
console.log(jobStatus);
while (jobStatus.state === 'InProgress') { // wait for it
await sleep(waitTimeMs);
jobStatus = await sfb2.getJobStatus(cji.instanceUrl, cji.apiVersion, cji.accessToken, 'ingest', job.id );
console.log(jobStatus);
}
console.log(`=== JOB Failure STATUS === `);
jobStatus = await sfb2.getJobFailureStatus(cji.instanceUrl, cji.apiVersion, cji.accessToken, job.id );
console.log(`=== JOB Failure STATUS for job: ${job.id} ===`);
console.log(jobStatus);
console.log(`=== JOB getUnprocessedRecords STATUS === `);
jobStatus = await sfb2.getUnprocessedRecords(cji.instanceUrl, cji.apiVersion, cji.accessToken, job.id );
console.log(`=== JOB getUnprocessedRecords STATUS for job: ${job.id} ===`);
console.log(jobStatus);
} catch (err) {
console.log(`ERROR in dataload : ${err}`);
}
}
// here we run it
dataload('input.csv');
```
## Results on the cli (console)
```
$ node index.js
=== CREATE JOB ===
{ id: '7503h000000RcUEAA0',
operation: 'insert',
object: 'Case',
createdById: '0053h000000IJFeAAO',
createdDate: '2020-03-18T04:23:56.000+0000',
systemModstamp: '2020-03-18T04:23:56.000+0000',
state: 'Open',
concurrencyMode: 'Parallel',
contentType: 'CSV',
apiVersion: 46,
contentUrl: 'services/data/v46.0/jobs/ingest/7503h000000RcUEAA0/batches',
lineEnding: 'LF',
columnDelimiter: 'COMMA' }
jobId: 7503h000000RcUEAA0
=== JOB STATUS ===
=== JOB STATUS for job: 7503h000000RcUEAA0 ===
{ id: '7503h000000RcUEAA0',
operation: 'insert',
object: 'Case',
createdById: '0053h000000IJFeAAO',
createdDate: '2020-03-18T04:23:56.000+0000',
systemModstamp: '2020-03-18T04:23:56.000+0000',
state: 'Open',
concurrencyMode: 'Parallel',
contentType: 'CSV',
apiVersion: 46,
jobType: 'V2Ingest',
contentUrl: 'services/data/v46.0/jobs/ingest/7503h000000RcUEAA0/batches',
lineEnding: 'LF',
columnDelimiter: 'COMMA',
retries: 0,
totalProcessingTime: 0,
apiActiveProcessingTime: 0,
apexProcessingTime: 0 }
=== PUT DATA ===
result: status: 201, statusText: Created
=== JOB STATUS ===
=== JOB STATUS for job: 7503h000000RcUEAA0 ===
{ id: '7503h000000RcUEAA0',
operation: 'insert',
object: 'Case',
createdById: '0053h000000IJFeAAO',
createdDate: '2020-03-18T04:23:56.000+0000',
systemModstamp: '2020-03-18T04:23:56.000+0000',
state: 'Open',
concurrencyMode: 'Parallel',
contentType: 'CSV',
apiVersion: 46,
jobType: 'V2Ingest',
contentUrl: 'services/data/v46.0/jobs/ingest/7503h000000RcUEAA0/batches',
lineEnding: 'LF',
columnDelimiter: 'COMMA',
numberRecordsProcessed: 0,
numberRecordsFailed: 0,
retries: 0,
totalProcessingTime: 0,
apiActiveProcessingTime: 0,
apexProcessingTime: 0 }
=== PATCH STATAE ===
{ id: '7503h000000RcUEAA0',
operation: 'insert',
object: 'Case',
createdById: '0053h000000IJFeAAO',
createdDate: '2020-03-18T04:23:56.000+0000',
systemModstamp: '2020-03-18T04:23:56.000+0000',
state: 'UploadComplete',
concurrencyMode: 'Parallel',
contentType: 'CSV',
apiVersion: 46 }
=== JOB STATUS ===
=== JOB STATUS for job: 7503h000000RcUEAA0 ===
{ id: '7503h000000RcUEAA0',
operation: 'insert',
object: 'Case',
createdById: '0053h000000IJFeAAO',
createdDate: '2020-03-18T04:23:56.000+0000',
systemModstamp: '2020-03-18T04:23:58.000+0000',
state: 'InProgress',
concurrencyMode: 'Parallel',
contentType: 'CSV',
apiVersion: 46,
jobType: 'V2Ingest',
lineEnding: 'LF',
columnDelimiter: 'COMMA',
numberRecordsProcessed: 0,
numberRecordsFailed: 0,
retries: 0,
totalProcessingTime: 0,
apiActiveProcessingTime: 0,
apexProcessingTime: 0 }
WAITING
{ id: '7503h000000RcUEAA0',
operation: 'insert',
object: 'Case',
createdById: '0053h000000IJFeAAO',
createdDate: '2020-03-18T04:23:56.000+0000',
systemModstamp: '2020-03-18T04:23:59.000+0000',
state: 'JobComplete',
concurrencyMode: 'Parallel',
contentType: 'CSV',
apiVersion: 46,
jobType: 'V2Ingest',
lineEnding: 'LF',
columnDelimiter: 'COMMA',
numberRecordsProcessed: 2,
numberRecordsFailed: 0,
retries: 0,
totalProcessingTime: 134,
apiActiveProcessingTime: 47,
apexProcessingTime: 0 }
=== JOB Failure STATUS ===
=== JOB Failure STATUS for job: 7503h000000RcUEAA0 ===
"sf__Id","sf__Error",Priority,Subject
=== JOB getUnprocessedRecords STATUS ===
=== JOB getUnprocessedRecords STATUS for job: 7503h000000RcUEAA0 ===
Subject,Priority
```
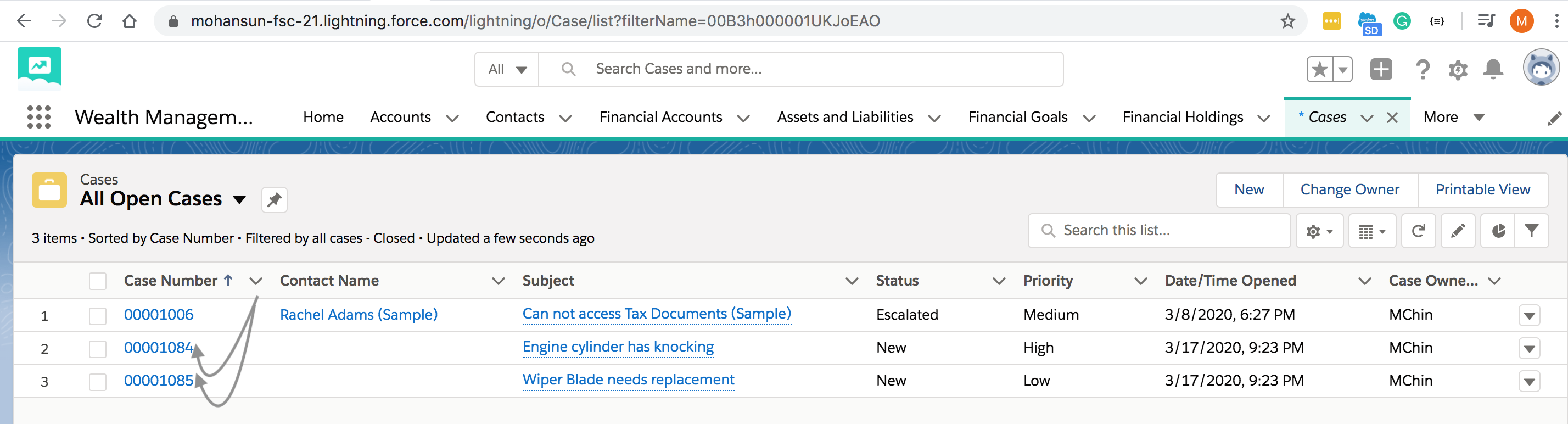
- Create node js project with the following code in index.js
```
//------------------------------------------------------------------
// Code for the aws lambda function using Salesforce BulkAPI 2.0
// Mohan Chinnappan (jul-21-2020)
//------------------------------------------------------------------
const sfb2 = require('sfbulk2js');
const AT = '00D3h000007R1Lu!AR0AQGyDeGEGhToyawRbG9rrc006T6.3Gi7V5JEU6X88ED7io7IUtzYDjhaLuQLQ_Ylp2TKux560e6rGzbQ8vAP7zd_hsYpy';
//AT can be read from env or from JWT flow (ref: https://github.com/mohan-chinnappan-n/bulkapi2-dx/blob/master/jwt.md)
const opts = {
instanceUrl: 'https://mohansun-ea-02-dev-ed.my.salesforce.com', // can be read from env
apiVersion: 'v49.0',
accessToken: `${AT}`,
contentType: 'CSV',
lineEnding: 'LF'
};
const waitTimeMs = 3000; // adjust it as required
exports.handler = async (event) => {
// TODO: read the s3 bucket data here (max size: 150 MB) into fdata
let fdata =
` Subject,Priority
Engine cylinder has knocking,High
Wiper Blade needs replacement,Low
`;
await data(fdata, 'Case', opts);
return { statusCode: 200, body: "Ok"};
};
function sleep(ms) {
//console.log('WAITING');
return new Promise(resolve => setTimeout(resolve, ms));
}
async function dataload(fdata, sobj, cji) {
try {
console.log(`=== CREATE JOB === `);
const job = await sfb2.createJob(cji.instanceUrl, cji.apiVersion, cji.accessToken, 'insert', sobj, cji.contentType, cji.lineEnding );
console.log(job);
console.log(`jobId: ${job.id}`);
console.log(`=== JOB STATUS === `);
let jobStatus = await sfb2.getJobStatus(cji.instanceUrl, cji.apiVersion, cji.accessToken, 'ingest', job.id );
console.log(`=== JOB STATUS for job: ${job.id} ===`);
console.log(jobStatus);
console.log(`=== PUT DATA === `);
const putDataStatus = await sfb2.putData(cji.instanceUrl, cji.accessToken, job.contentUrl, fdata );
console.log(`=== JOB STATUS === `);
jobStatus = await sfb2.getJobStatus(cji.instanceUrl, cji.apiVersion, cji.accessToken, 'ingest', job.id );
console.log(`=== JOB STATUS for job: ${job.id} ===`);
console.log(jobStatus);
console.log(`=== PATCH STATAE === `);
const patchDataStatus = await sfb2.patchState(cji.instanceUrl, cji.apiVersion, cji.accessToken, job.id, 'UploadComplete' );
console.log(patchDataStatus);
console.log(`=== JOB STATUS === `);
jobStatus = await sfb2.getJobStatus(cji.instanceUrl, cji.apiVersion, cji.accessToken, 'ingest', job.id );
console.log(`=== JOB STATUS for job: ${job.id} ===`);
console.log(jobStatus);
// TODO: This waiting may not required for lambda function to avoid lambda timeout
// Modify it as needed
while (jobStatus.state === 'InProgress') { // wait for it
await sleep(waitTimeMs);
jobStatus = await sfb2.getJobStatus(cji.instanceUrl, cji.apiVersion, cji.accessToken, 'ingest', job.id );
console.log(jobStatus);
}
console.log(`=== JOB Failure STATUS === `);
jobStatus = await sfb2.getJobFailureStatus(cji.instanceUrl, cji.apiVersion, cji.accessToken, job.id );
console.log(`=== JOB Failure STATUS for job: ${job.id} ===`);
console.log(jobStatus);
console.log(`=== JOB getUnprocessedRecords STATUS === `);
jobStatus = await sfb2.getUnprocessedRecords(cji.instanceUrl, cji.apiVersion, cji.accessToken, job.id );
console.log(`=== JOB getUnprocessedRecords STATUS for job: ${job.id} ===`);
console.log(jobStatus);
} catch (err) {
console.log(`ERROR in dataload : ${err}`);
}
}
```
- Function Code
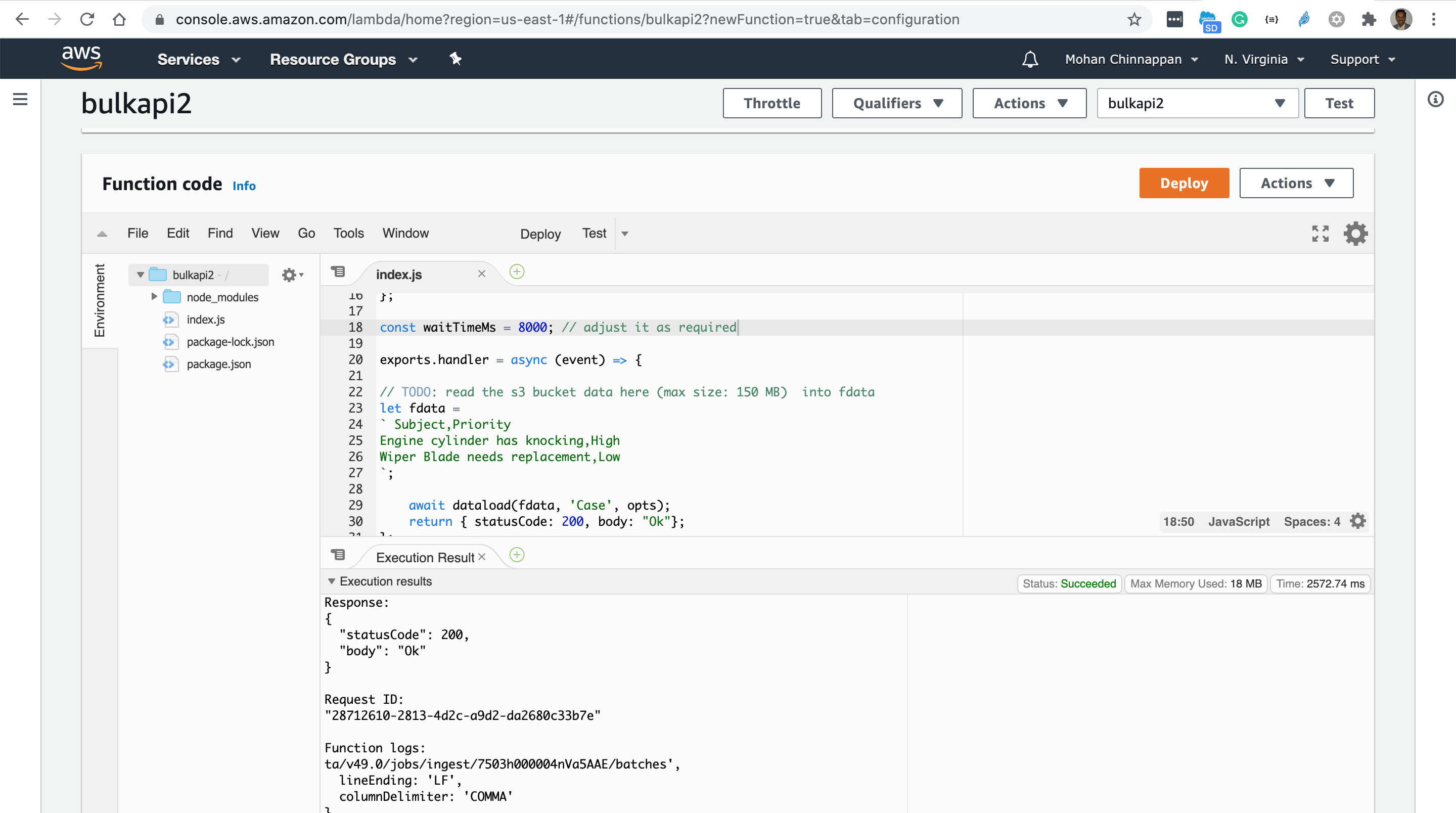
- package.json
```json
{
"name": "aws-bulkapi2",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "Mohan Chinnappan",
"license": "MIT",
"dependencies": {
"sfbulk2js": "0.0.1"
}
}
```
### Same package is available in python!
- More info at: [Salesforce Bulk API 2.0](https://medium.com/@mohan.chinnappan.n/salesforce-bulk-api-2-0-95a7a81b9bb9)
```
"""
bulkapi2-usage
author: mohan chinnappan (mar-18-2020)
pip install sfbulk2
pip install Faker
"""
instance_url = 'https://mohansun-fsc-21.my.salesforce.com'
## access_token can come from env var
access_token = '00D3hmangledDC8N!ARcAQFAqd7iOlatMgWpfXmjfk0YRgtfnU0ntLE3OBZjJgn3Shqe9ssq7ZowsmoEhoAn_nHpjoIwVB40gBpmFbwx4sZR6b9RE'
## let us import SFBulk2
from sfbulk2 import SFBulk2
sfba2 = SFBulk2(api_version='v47.0', instance_url=instance_url, access_token=access_token)
## create bulkapi2 job
job_id = sfba2.create_job(operation='insert', obj='Case')
print ('job_id: {}'.format(job_id))
## let us look at the job status
res = sfba2.get_job_status(job_id=job_id, optype='ingest')
print (res.json())
contentUrl = res.json()['contentUrl']
print(contentUrl)
## Insert Data
### you can read it from the database (Postgres, Spanner, MySQL...) and create this file
data ="""Subject,Priority
VPN2 Issues,High
Proxy Server2 Issues,Low
HVD2 Issues,High
"""
print (data)
## let us upload the data
put_res = sfba2.put_data(data=data, contentUrl=contentUrl)
print (put_res.content)
## get the job status
res = sfba2.get_job_status(job_id=job_id, optype='ingest')
print(res.json())
## set the state to 'UploadComplete'
patch_res = sfba2.patch_state(job_id=job_id, state="UploadComplete")
print(patch_res.json())
## get the job status
res = sfba2.get_job_status(job_id=job_id, optype='ingest')
print(res.json())
## you will see the something like this
"""
{'apexProcessingTime': 0,
'apiActiveProcessingTime': 60,
'apiVersion': 47.0,
'columnDelimiter': 'COMMA',
'concurrencyMode': 'Parallel',
'contentType': 'CSV',
'createdById': '0053h000000IJFeAAO',
'createdDate': '2020-03-18T12:16:32.000+0000',
'id': '7503h000000RdYUAA0',
'jobType': 'V2Ingest',
'lineEnding': 'LF',
'numberRecordsFailed': 0,
'numberRecordsProcessed': 3,
'object': 'Case',
'operation': 'insert',
'retries': 0,
'state': 'JobComplete',
'systemModstamp': '2020-03-18T12:21:50.000+0000',
'totalProcessingTime': 168}
"""
## check the failure status
failure_res = sfba2.get_failure_status(job_id=job_id)
print(failure_res.content)
## you will see something like this:
"""
b'"sf__Id","sf__Error",Priority,Subject\n'
"""
```
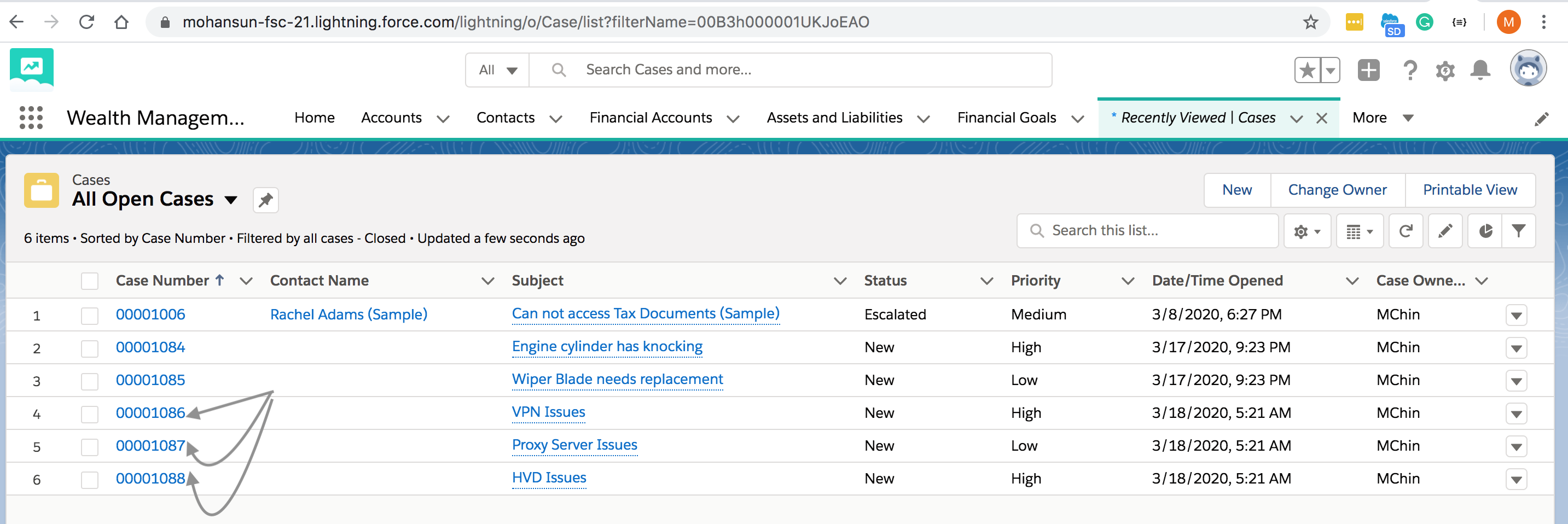
- [Bulk API 2.0](https://developer.salesforce.com/docs/atlas.en-us.api_bulk_v2.meta/api_bulk_v2/get_job_info.htm)
- [Salesforce Bulk API 2.0](https://medium.com/@mohan.chinnappan.n/salesforce-bulk-api-2-0-95a7a81b9bb9)
- Maximum number of records uploaded per rolling 24-hour period
- **150,000,000**
- Maximum number of times a batch can be retried. [See How Requests Are Processed](https://developer.salesforce.com/docs/atlas.en-us.api_bulk_v2.meta/api_bulk_v2/how_requests_are_processed.htm).
- **The API automatically handles retries. If you receive a message that the API retried more than 10 times, use a smaller upload file and try again.**
- Maximum file size
- **150 MB**
- Maximum number of characters in a field
- **32,000**
- Maximum number of fields in a record
- **5,000**
- Maximum number of characters in a record
- **400,000**
- [Refer: Bulk API 2.0 Limits](https://developer.salesforce.com/docs/atlas.en-us.api_bulk_v2.meta/api_bulk_v2/bulk_api_2_limits.htm)